POSTS
生产环境内存泄露分析
项目基础架构: Java+gRPC+Rails
因生产环境频繁出现宕机的情况,平均一周需要重启下服务器,这谁顶得住啊。。这个问题必须解决。在开始分析问题之前,我们先重启一次服务器,然后每天记录cpu、内存使用情况。内存记录如下:
重启后第一次内存展示:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 4.3G 2.7G 14M 837M 3.2G
Swap: 0B 0B 0B
第二天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.2G 1.1G 14M 1.5G 2.3G
Swap: 0B 0B 0B
第三天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.6G 691M 14M 1.6G 1.9G
Swap: 0B 0B 0B
第四天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.8G 330M 14M 1.7G 1.7G
Swap: 0B 0B 0B
第五天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.4G 181M 14M 1.2G 1.0G
Swap: 0B 0B 0B
第六天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.8G 211M 14M 819M 704M
Swap: 0B 0B 0B
从上面可以看到内存占用每天递增,并不会释放,基本可以断定是内存泄露了,当内存消耗光服务器就卡死了。接下来我们就开始具体分析哪里出了问题,通过top命令查看进程内存占用情况:
➜ ~ top (然后按M,按照内存占用倒序排序展示)
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1492 uugm 20 0 5784920 1.767g 9444 S 0.0 22.7 28:10.18 java
28426 root 20 0 3069812 1.201g 24992 S 0.0 15.4 9:24.44 ruby
2501 uugm 20 0 5781664 1.083g 9564 S 0.0 13.9 12:35.30 java
2672 uugm 20 0 5064376 857924 9216 S 0.0 10.5 4:11.96 java
2628 uugm 20 0 1177596 321708 9728 S 0.0 3.9 1:15.28 node
1771 uugm 20 0 4452920 255852 9180 S 0.0 3.1 3:48.27 java
其实通过内存占用记录(这里top的数据记录就没有粘贴了),可以判断有两个java进程(1492、2501)内存一直递增,一个ruby进程(28426)一直递增。经过查看这两个java进程都使用到了grpc,其他没有使用grpc的java进程内存没有递增,很有可能是grpc的问题,当然现在只是我的猜测,我们需要进一步分析。
1.将pid为1492的java进程的整个heap堆数据dump出来,文件形式为二进制文件
jmap -dump:format=b,file=heap.bin 1492
# 会生成heap.bin文件,可能会比较大,这里是1.3g
-rw------- 1 user group 1.3G Nov 25 20:52 heap.bin
2.下载二进制文件到本地
scp user@xxx.xxx.com:/home/user/heap.bin ../mat/
3.下载Memory Analyzer (MAT)内存分析软件。MAT下载
4.然后通过MAT打开heap.bin文件
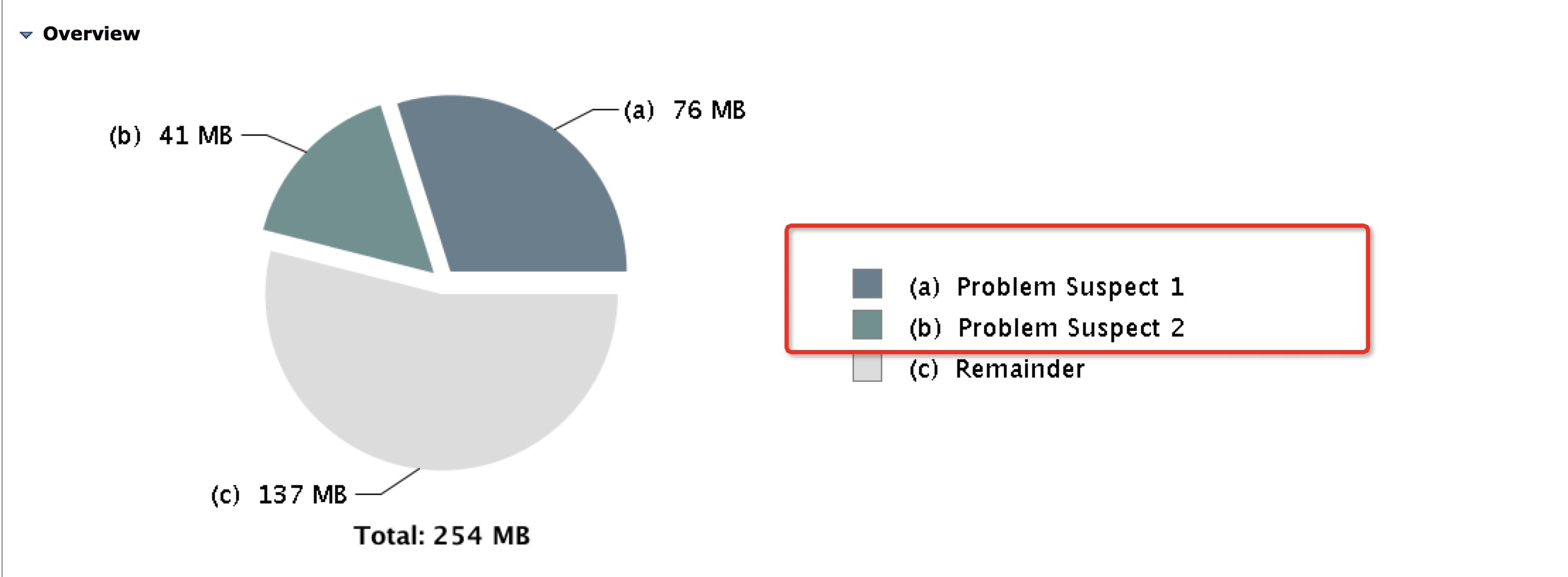
可以看到有两个可疑问题
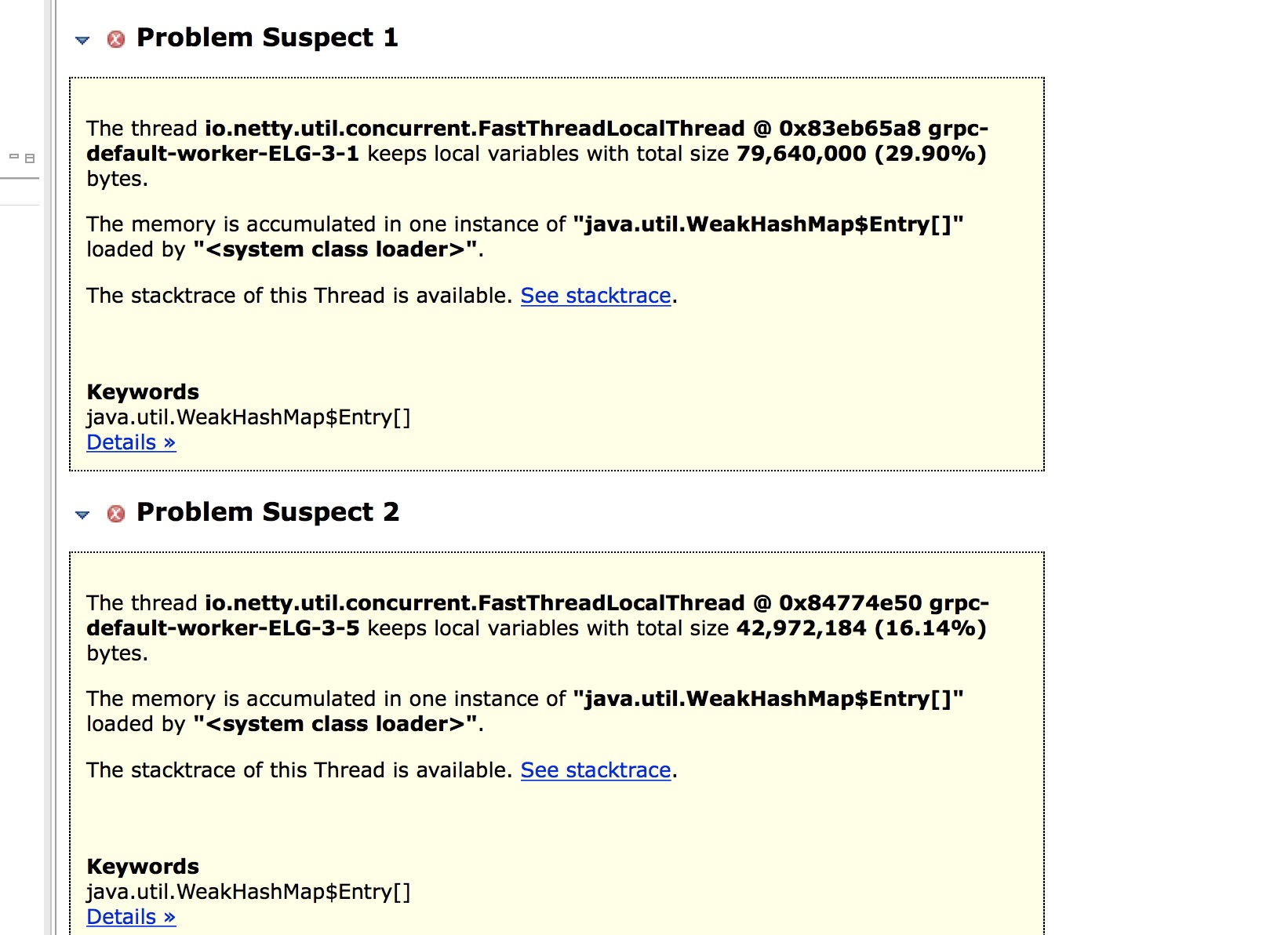

正如我们的猜想一样,确实和grpc有关,并且是grpc中依赖的netty库有关。由上图可知netty中的worker的WeakHashMap数组中存在大量对象没有被回收,从而导致内存一直增加。
5.经过一番google,然后找到了是netty版本的问题,我们项目中grpc版本是1.0.0,其中它依赖的netty版本是4.1.3.Final,此版本存在内存泄露。具体可以看https://github.com/grpc/grpc-java/issues/2358。
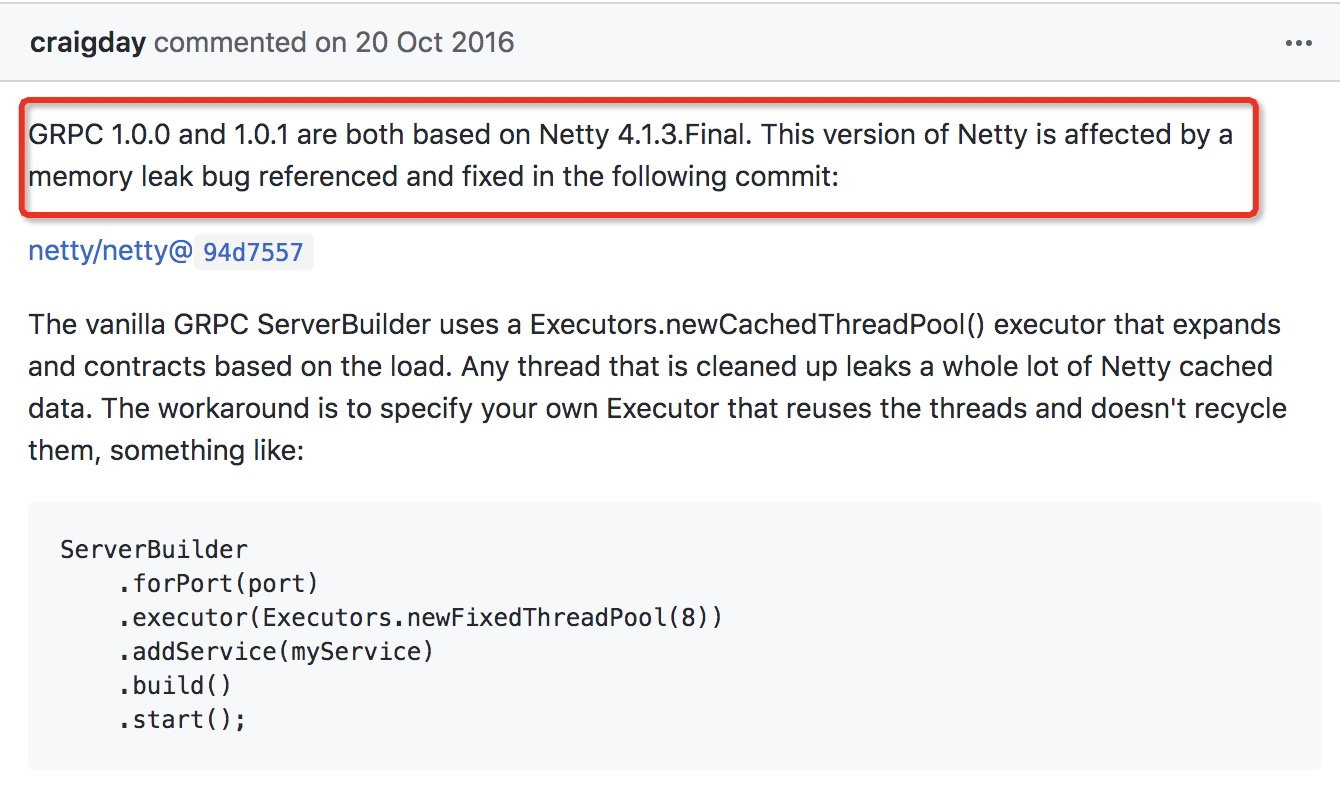
上面提到说可以指定固定的线程池来解决它,也可以更新netty版本。
but the issue is fixed in Netty 4.1.6.Final.
在Netty 4.1.6.Final版本修复了这个bug,我们就更新grpc版本来解决它。grpc版本应该小幅度提升并保证能解决此bug,以免项目中使用的一些方法被新版本废弃。我们就提升grpc到1.0.3,此版本netty为4.1.6.Final

好了,目前java进程的内存泄露分析到此为止,我们还有个ruby进程,内存也是持续增加,接下来继续分析。
6.难道ruby进程也存在内存泄露?
我网上搜了一些ruby内存泄露的帖子,https://ruby-china.org/topics/27057, https://ruby-china.org/topics/35238
他们的结论差不多都是:
* 减少全局对象(在Ruby中一个对象一旦被全局对象引用,它就不会被垃圾回收)
* 减少创建大的对象
* 减少创建的对象
* 数据库查询尽量使用limit限制查询结果条数
* 避免n+1查询
其实我们Rails项目中确实用到了一些全局对象并且是大对象,会不会是这个问题?但这些都是必须的,很多接口都要用到这些大对象,如果不用全局变量,那么每次请求都要新创建一个大对象,内存占用一样的大,了解了下ruby的gc机制,这些大对象用了之后可能还不会完全释放,内存占用也许会更大。
这就僵住了呀,那该怎么解决呢?
我无奈之下重启了下puma,看看有什么不同。
touch tmp/restart.txt
我惊奇的发现服务器内存瞬间释放了2G
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 4.8G 1.9G 14M 1.1G 2.6G
Swap: 0B 0B 0B
难道是puma的问题?
我又开始了搜索,哈哈。找到puma内存占用相关的帖子,https://ruby-china.org/topics/35236
引用别人的结论:
puma 和 unicorn 都不会主动降低操作系统内存占用, 但会复用已经申请过的内存.
所以会随着每分钟请求量的增加导致内存不断上升. 如果超出某个极限, 则有可能导致
内存爆掉. 可以考虑使用puma_worker_killer进行控制.
似乎又有点思路了,就算没有真正解决内存泄露的问题,也可以用puma_worker_killer来控制内存占用来解决服务器宕机的问题。
puma_worker_killer github地址: https://github.com/schneems/puma_worker_killer
7.按照puma_worker_killer文档,稍作修改puma.rb
before_fork do
PumaWorkerKiller.config do |config|
config.ram = 1024*2 # mb
config.frequency = 20 # seconds
config.percent_usage = 0.98
config.rolling_restart_frequency = false
config.pre_term = -> (worker) { File.open("#{Rails.root}/log/workers-killed.log", 'w') { |file| file.write("Worker #{worker.inspect} being killed") } }
end
PumaWorkerKiller.start
end
threads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }
threads 0, threads_count
bind 'unix:/tmp/puma.uugm-tz.sock'
environment ENV.fetch("RAILS_ENV") { "production" }
daemonize true
workers ENV.fetch("WEB_CONCURRENCY") { 2 }
preload_app!
plugin :tmp_restart
8.经过上面更改之后的内存记录
第一天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.2G 806M 14M 1.8G 2.3G
Swap: 0B 0B 0B
➜ ~ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3577 uugm 20 0 5750012 1.217g 19884 S 0.0 15.6 5:07.58 java (rpc)
7354 root 20 0 2716908 984140 11928 S 0.0 12.0 3:36.96 ruby (puma: worker 0)
2672 uugm 20 0 5064376 857924 9216 S 0.0 10.5 4:59.27 java (ext-jcb)
2532 uugm 20 0 5778256 691360 22564 S 0.0 8.5 2:23.33 java (play-rpc)
8558 root 20 0 2318568 591512 11860 S 0.0 7.2 0:57.80 ruby (puma: worker 1)
4015 uugm 20 0 4452948 379472 19300 S 0.0 4.6 0:49.91 java
2628 uugm 20 0 1181244 329372 13344 S 0.0 4.0 1:28.98 node
3705 root 20 0 1109064 131188 4808 S 0.0 1.6 0:08.20 ruby
第二天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.0G 1.0G 14M 1.8G 2.5G
Swap: 0B 0B 0B
➜ ~ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3577 uugm 20 0 5755144 1.269g 19884 S 0.0 16.3 7:27.48 java (rpc)
2672 uugm 20 0 5064376 857924 9216 S 0.3 10.5 5:14.08 java (ext-jcb)
8558 root 20 0 2453736 733712 11896 S 0.0 9.0 3:17.42 ruby (puma: worker 1)
2532 uugm 20 0 5780304 672312 22564 S 0.0 8.2 3:25.27 java (play-rpc)
12938 root 20 0 2321756 576872 11844 S 0.3 7.1 0:34.98 ruby (puma: worker 0)
4015 uugm 20 0 4452948 358768 19300 S 0.3 4.4 1:06.05 java
2628 uugm 20 0 1183744 333516 13344 S 0.0 4.1 1:31.31 node
3705 root 20 0 1109064 131216 4808 S 0.0 1.6 0:12.56 ruby
这里可以发现puma worker-0 进程的pid由7354变为12938,是因为当此worker内存占用过高时,puma_worker_killer将其重启了,从worker kill日志信息也可以看到。(之后worker pid发生变化都是这个原因,不在赘述了)
第三天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.6G 763M 14M 1.4G 1.9G
Swap: 0B 0B 0B
第四天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.4G 965M 14M 1.5G 2.1G
Swap: 0B 0B 0B
第五天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.1G 1.0G 14M 1.6G 2.4G
Swap: 0B 0B 0B
第六天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.5G 1.0G 14M 1.2G 1.9G
Swap: 0B 0B 0B
第七天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.1G 134M 14M 1.5G 1.3G
Swap: 0B 0B 0B
经过一周的观察,并没有发现服务器宕机,是好事。但是我们看到rpc进程内存还是在递增,ruby的内存占用经过puma_worker_killer算是得到了缓解。那我们重新看下java进程的内存占用问题。
9.重新dump一份堆二进制文件,打开MAT软件。
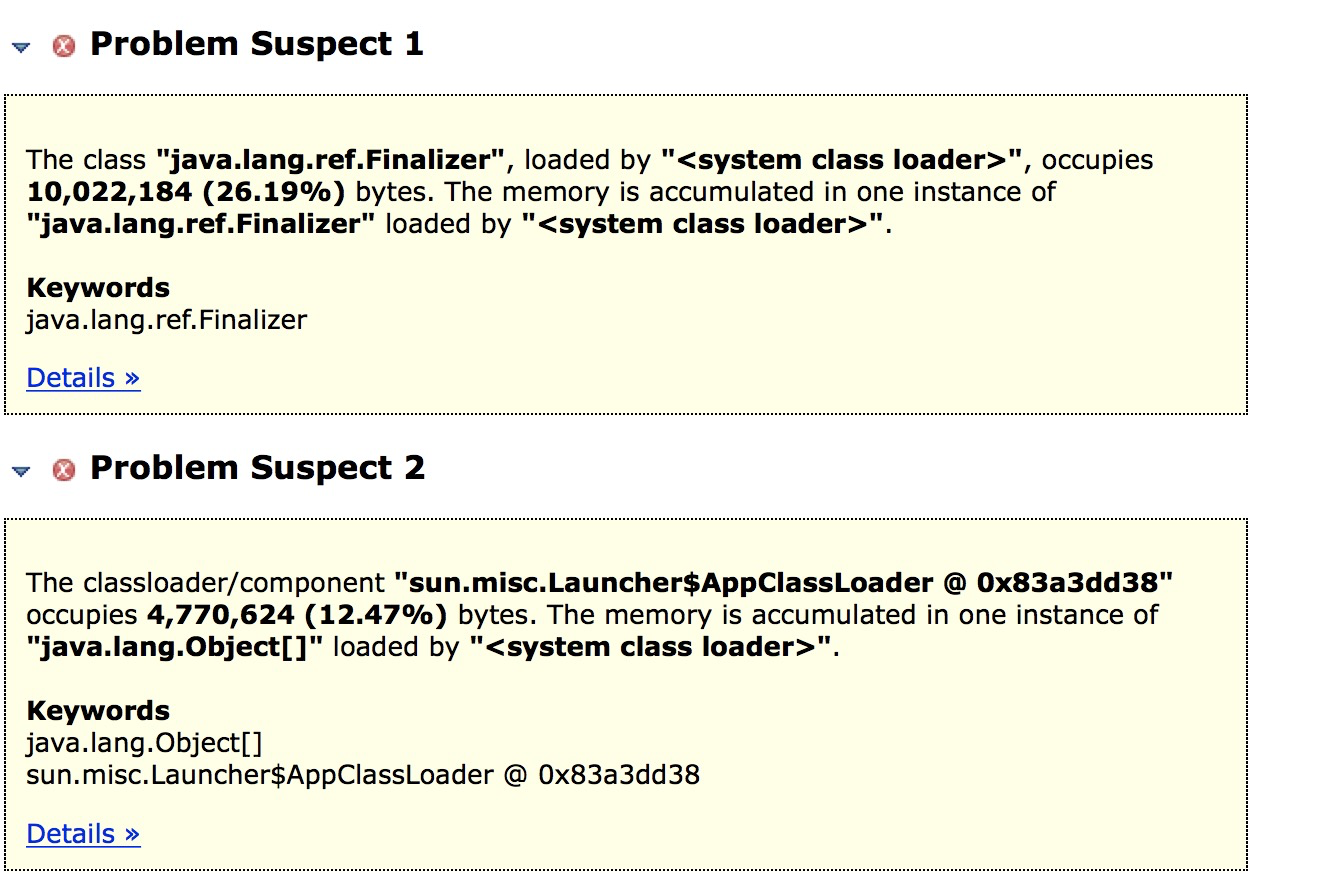
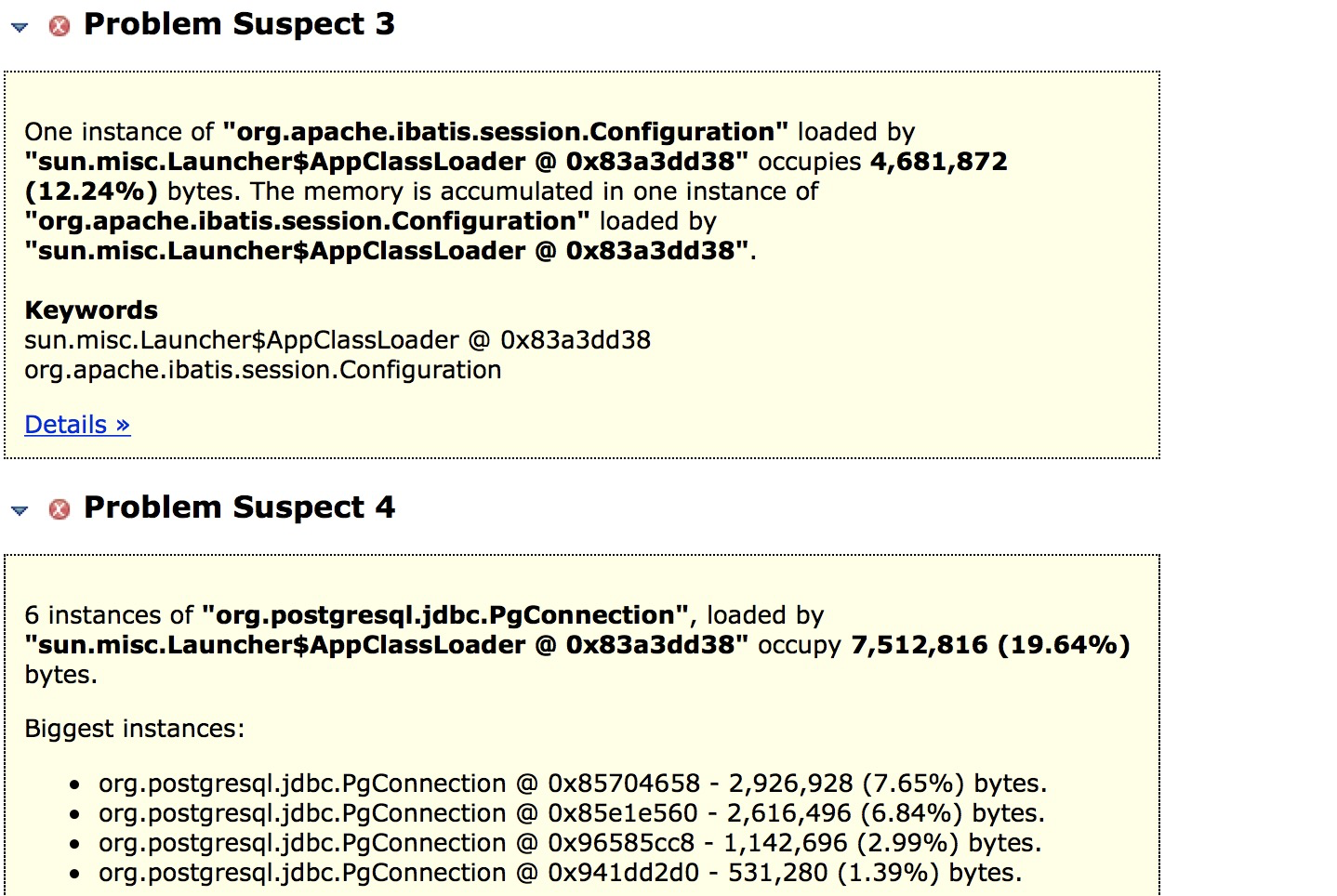

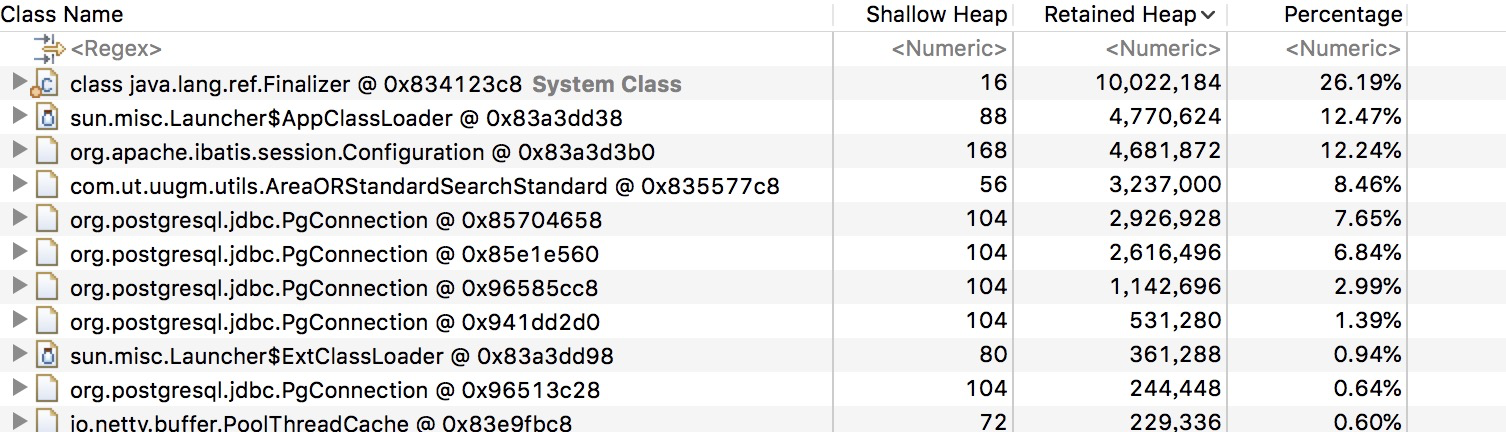
可以看到跟之前的可疑问题不一样了,java.lang.ref.Finalizer和org.postgresql.jdbc.PgConnection这两个类的对象占用率比较高。结合上面的可疑点3、可疑点4,很有可能是数据库连接未关闭的问题。
打开数据库连接对象的具体信息:
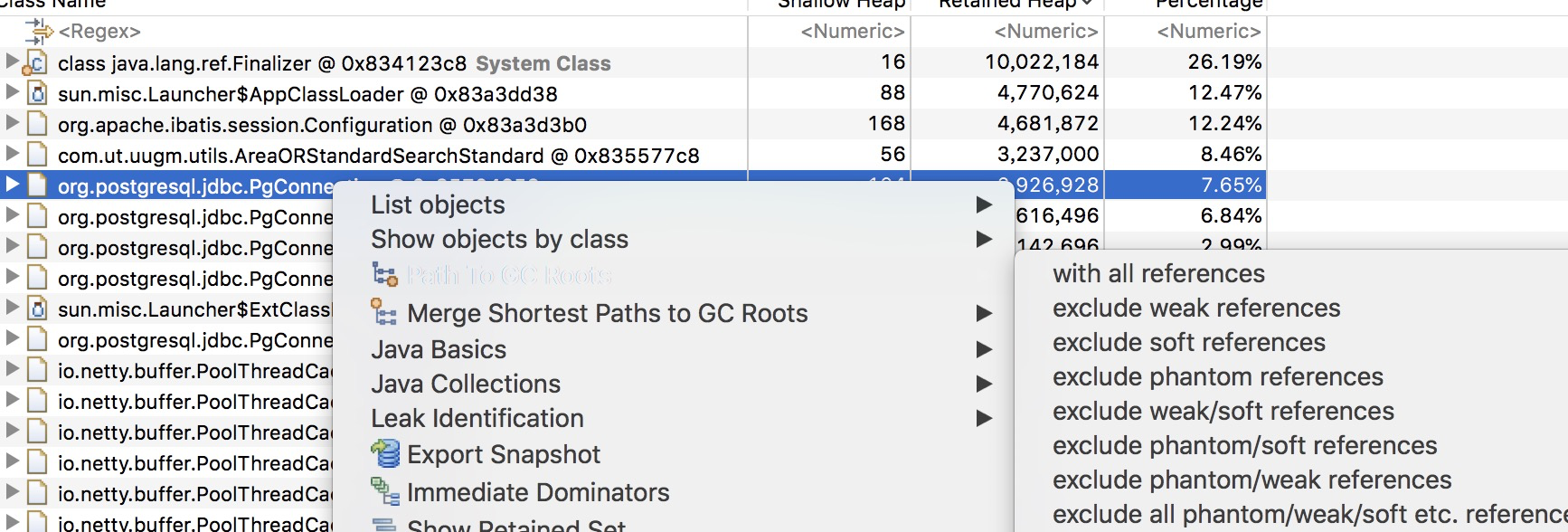
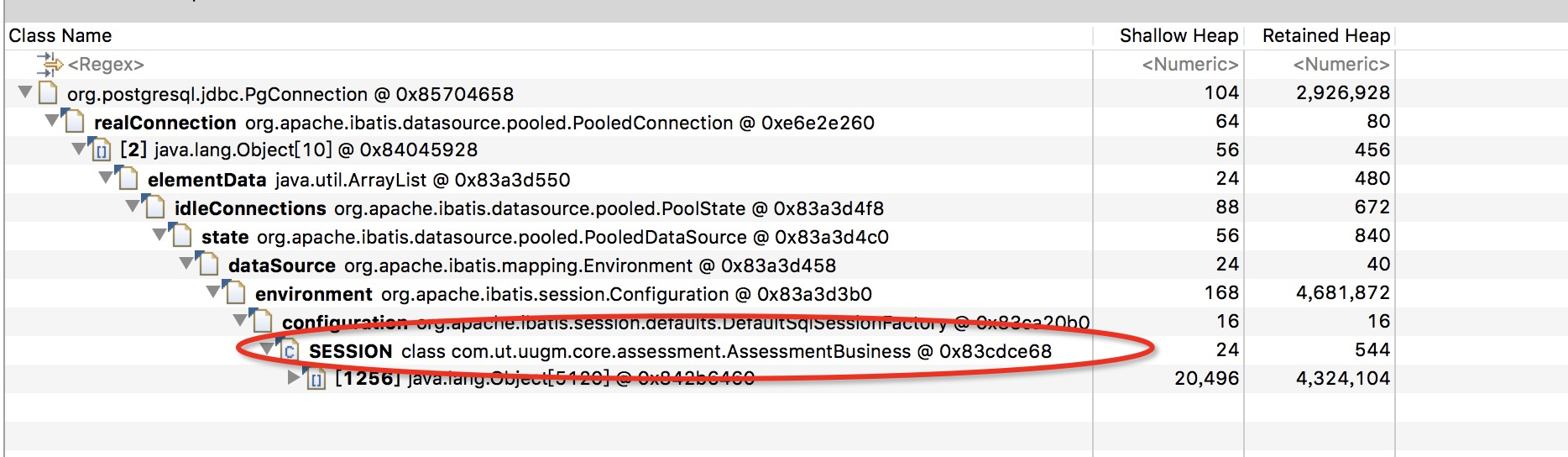
上图可以看到我们项目com.ut.uugm.core.assessment.AssessmentBusiness类可能存在问题。我们就具体看下代码:
private static final SqlSessionFactory SESSION = MybatisConfigure.sqlSessionFactory();
public Optional<InternalBusiness> getInternalBusinessScore(long assessmentId, String packageName) {
try (SqlSession sqlSession = SESSION.openSession(true)) {
do something
}
}
在AssessmentBusiness类中可以看到很多用try-with-resources方式来自动关闭资源,首先我们需要了解为啥这种方式能自动关闭资源,是因为资源类实现了java.lang.AutoCloseable接口,那么mybatis的org.apache.ibatis.session.SqlSession接口是否继承了此接口呢
public interface SqlSession extends Closeable {
<T> T selectOne(String var1);
<T> T selectOne(String var1, Object var2);
something...
}
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
可见SqlSession继承了此接口。通过测试,在try语句块后不能再次调用sqlSession,资源应该是被关闭了的。
既然问题定位到这里了,还是要看看代码的其他地方,我们看到这里定义了个静态常量:
private static final SqlSessionFactory SESSION = MybatisConfigure.sqlSessionFactory()
我们知道静态常量存在方法区(在Hotspot中,jdk1.8以下被称为永久代,jdk1.8以上被称为元空间),此区域存放类的基本信息,GC频率很低。如果常量没有被引用则可以被回收,因为很多业务类都使用此方式创建SqlSessionFactory,并且MybatisConfigure.sqlSessionFactory()也创建的是一个单例对象,所以多个类的SESSION应该指向是同一个SqlSessionFactory,通过MAT看SESSION哈希地址相同也可以验证。那么多个类都持有此SESSION,此常量不被回收。你可能会问:Mybatis的SqlSessionFactory不是一个应用程序就该产生一个吗,然后由它创建SqlSession,此SESSION符合要求。但是需要注意的是,这里不是SqlSessionFactory产生一个实例的问题,而是常量没被回收导致其引用的数据库连接类也没被释放的问题。
这里我们稍微改下代码,去掉静态常量,使用下面方式获取session:
try (SqlSession sqlSession = MybatisConfigure.sqlSessionFactory().openSession(true)) {
do something...
}
修改获取session代码后的内存记录:
第一天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.1G 1.4G 14M 1.3G 2.4G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22467 uugm 20 0 5776732 1.027g 19832 S 0.0 13.2 4:25.98 java (rpc)
27514 root 20 0 2645540 947872 10964 S 0.0 11.6 2:14.79 ruby
22641 uugm 20 0 5781796 861156 22760 S 0.0 10.5 2:49.04 java (play)
第二天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.7G 689M 14M 1.5G 1.8G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22467 uugm 20 0 5778780 1.108g 19832 S 0.3 14.2 6:58.27 java (rpc)
32118 root 20 0 2842148 1.001g 11024 S 0.0 12.8 4:45.64 ruby
22641 uugm 20 0 5783844 0.985g 22760 S 0.0 12.6 4:58.51 java (play)
32592 root 20 0 2583072 873044 11220 S 0.0 10.7 3:02.37 ruby
第三天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.7G 332M 14M 1.7G 1.7G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22467 uugm 20 0 5787984 1.197g 19828 S 0.0 15.4 14:40.34 java (rpc)
22641 uugm 20 0 5783844 1.161g 22740 S 0.0 14.9 11:20.52 java (play)
17140 root 20 0 2848292 1.016g 10992 S 0.0 13.0 2:34.20 ruby
2672 uugm 20 0 5064376 890256 7380 S 0.0 10.9 31:20.52 java
第四天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.0G 213M 14M 1.6G 1.5G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22467 uugm 20 0 5787984 1.223g 17488 S 0.3 15.7 18:37.58 java (rpc)
22641 uugm 20 0 5783844 1.197g 18024 S 5.3 15.4 13:44.44 java (play)
22907 root 20 0 2843176 1.012g 11208 S 0.0 13.0 2:31.84 ruby
2672 uugm 20 0 5064376 910584 7380 S 0.0 11.1 31:58.08 java
第五天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.0G 183M 14M 1.6G 1.4G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22641 uugm 20 0 5783844 1.357g 15940 S 0.0 17.4 16:08.37 java (play)
22467 uugm 20 0 5787984 1.232g 17480 S 0.0 15.8 23:28.00 java (rpc)
29272 root 20 0 2850588 987.8m 11248 S 0.0 12.4 3:48.20 ruby
2672 uugm 20 0 5064376 917720 7388 S 0.0 11.2 32:33.34 java
第六天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.1G 325M 14M 1.3G 1.3G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22641 uugm 20 0 5783844 1.390g 16064 S 0.3 17.8 18:08.42 java (play)
22467 uugm 20 0 5788248 1.276g 17520 S 0.0 16.4 26:52.01 java (rpc)
3577 root 20 0 2977596 1.104g 11056 S 0.0 14.2 3:24.49 ruby
2672 uugm 20 0 5064376 917720 7388 S 0.0 11.2 33:04.85 java
第七天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 6.1G 311M 14M 1.4G 1.4G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22641 uugm 20 0 5783844 1.350g 9932 S 0.3 17.3 20:14.24 java (play)
22467 uugm 20 0 5788248 1.277g 9712 S 0.3 16.4 29:37.44 java (rpc)
9375 root 20 0 2783884 0.986g 11060 S 0.0 12.6 2:59.86 ruby
2672 uugm 20 0 5064376 917720 7388 S 0.0 11.2 33:38.38 java
第八天:
➜ ~ free -h
total used free shared buff/cache available
Mem: 7.8G 5.5G 1.5G 14M 824M 1.9G
Swap: 0B 0B 0B
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22467 uugm 20 0 5788248 1.272g 9712 S 0.0 16.3 30:33.06 java(rpc)
22641 uugm 20 0 5783844 1.250g 9932 S 0.0 16.0 22:23.04 java (play)
2672 uugm 20 0 5064376 917720 7388 S 0.0 11.2 34:14.03 java
由上面记录可知,应用rpc内存占用趋于稳定,不再增加,说明内存泄露问题得到了解决。